如果我們希望網站不要被搜尋網站收錄,例如網站屬於私人或是私密的內容,可以在網站的根目錄放置一個robot.txt來設定。robots.txt 檔案位於網站根目錄,能夠向搜尋引擎檢索器表明不希望檢索器存取的網站內容。但如果使用不當,很可能讓整個網站被搜尋引擎拒絕!
設定狀況
在Weebly的網站,也有robots.txt,若設定不當時以下便是被拒絕時的狀況:當用「info:網址」時,即會顯示因為robots.txt無法網站訊息。

我們實際用瀏覽器檢視該網站的robots.txt,發現它的結果如下:

參數的意義如下:
User-agent:代表搜尋引擎的名稱
Disallow:代表網站目錄下的所有檔案接拒絕被搜尋
而目前的設定就是拒絕全部的搜尋引擎登錄資料。
User-agent: *
Disallow: /
解決方法
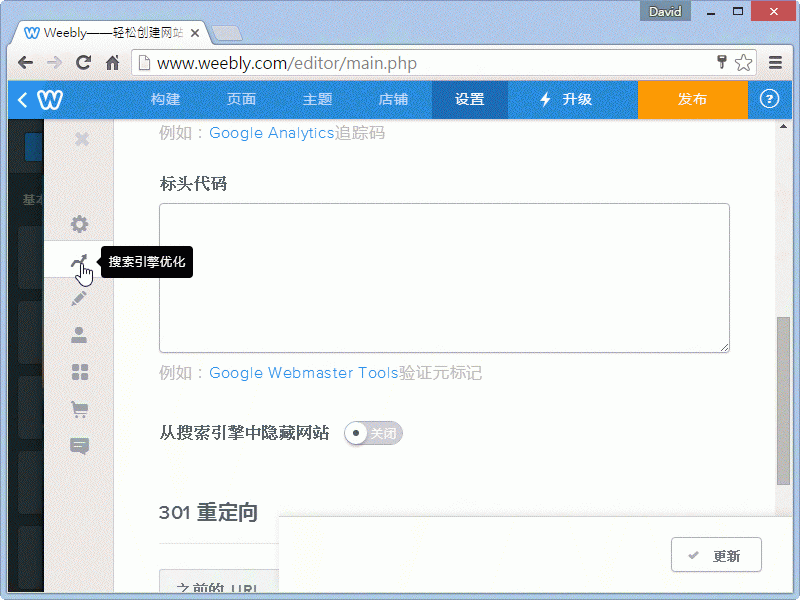
進入Weebly的網站編輯畫面,選按上方的 設置 單元,再選按左方的 搜索引擎優化,請關閉 以搜索引擎中隱藏網站,再按 更新,最後按 發佈 即可。
如下圖我們再讀取網站的robots.txt,果然已經開啟了所有的設定。

是不是很簡單呢?如果想要讓你的網站不被搜尋引擎拒絕,別忘了設定一下喔!
相關書籍
